Apache Hadoop – Ein Framework für die Implementierung von Big Data Analytics
KEY FACTS
-
The growing complexity of exploitable data in the business world requires a future oriented list of companies in the area of Big Data Analytics
-
The high infrastructural requirements for traditional technologies to support Big Data Paradigms can only be implemented at great expense
-
Apache Hadoop framework addresses current and future technological challenges of Big Data and enables the integration of big data analytics in businesses
REPORT
Der Rohstoff Daten und die Fähigkeiten der Analyse avancieren zu einem wichtigen Wettbewerbsfaktor für Unternehmen. In der Bank- und Finanzindustrie etwa werden massive Datenmengen durch vielfälltige Services und Dienstleistungen in den Bereichen Mobile Banking, Kreditkarten, Investition und Versicherungen erzeugt. Der Verwendungszweck dieser gesammelten Daten erstreckt sich vom Betrieb der Services über die Verbesserung des Angebots an den Kunden bis hin zur Fraud-Detection und Risikoanalyse. Die Menge an heute verwertbaren Datenmengen nimmt stetig zu, zeichnet sich durch verschiedenartigste Datentypen aus und erfordert hohe Flexibilität in der Analysefähigkeit. Unternehmen insgesamt müssen sich in dieser Domäne zukunftsorientiert aufstellen, denn durch das Geflecht zukünftiger technologischer Innovationen wird der Trend „Big Data“ weiter getrieben.
Entgegen der Namensgebung beziehen sich die Herausforderungen von Big Data nicht allein auf massive Datenmengen im Peta- oder Hexabyte-Bereich. Im Besonderen handelt es sich um Daten hoher Varietät mit verschiedensten Datenformaten in strukturierter sowie unstrukturierter Form. Hinzu kommt eine hohe und kontinuierlich anhaltende Änderungshäufigkeit der gespeicherten Daten und die unabdingbare Anforderung, valide, fehlertolerante Datenanalysen durchzuführen. Diese hohe Komplexität der „Big Data Analytics“ stellt hohe Anforderungen an Hardware-Ressourcen wie Speicher, RAM und CPU, womit eine solide Infrastruktur um so mehr zum kritischen Faktor für Performance und Verfügbarkeit avanciert. In diesem Zusammenhang rücken konsequenterweise die hohen Kosten für die Implementierung einer hoch performanten, hoch verfügbaren und hoch skalierbaren Infrastruktur in die Betrachtung. In diesem Bereich bieten sich Lösungen des Cloud-Computing an.
In der Sphäre von Big Data, Cluster- und Cloud-Computing hat sich Apache Hadoop als Open Source-Lösung für verteilte Systeme erfolgreich etabliert. Die Master/Slave-Architektur verspricht ein hohes Maß an Skalierbarkeit, Verfügbarkeit und Fehlertoleranz. Die Erweiterung der Speicherkapazität, Erhöhung der I/O-Kapazitäten sowie Steigerung der Rechenleistung können kosteneffizient durch das simple Hinzufügen von Standardhardware realisiert werden.
In Abbildung 1 ist ein abstrahiertes Hadoop-Ökosystem für die Implementierung einer „Big Data Analytics“ dargestellt. Die gundlegenden Bestandteile der Apache Hadoop-Lösung sind das Hadoop Distributed File System (HDFS) und das Map-Reduce-Framework. Das HDFS bildet das „File Storage System“ und ist in der Lage, mit sehr großen (strukturierten wie unstrukturierten) Datenmengen umzugehen. In den letzten Jahren hat sich das HDFS zum Defacto-Standard für Big Data-Technologien entwickelt.
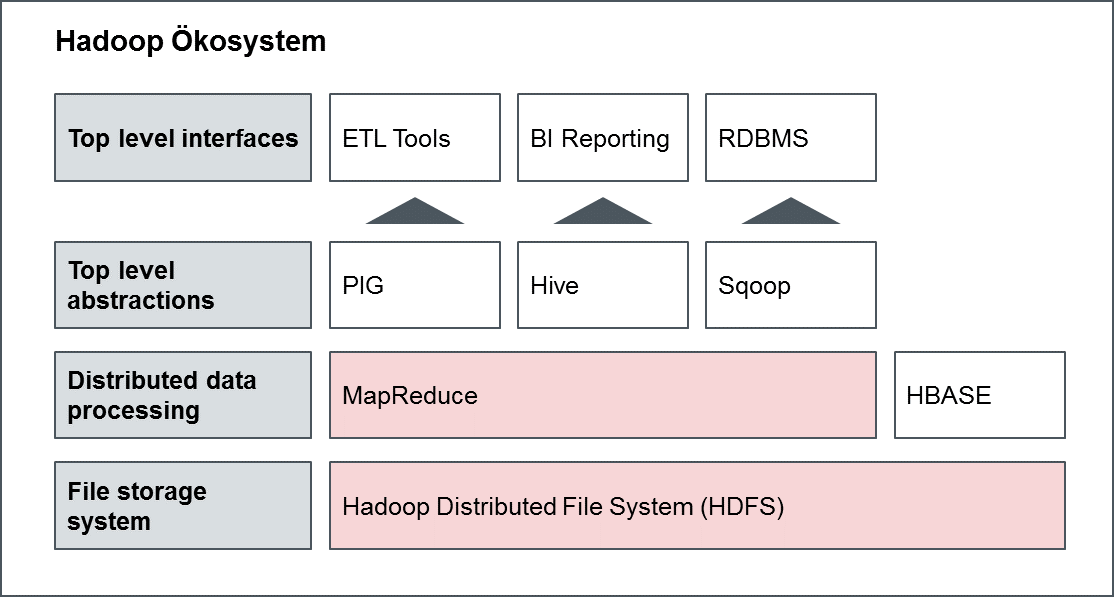
Abbildung 1: Darstellung eines möglichen Ökosystem Apache Hadoop
Map-Reduce ist ein Framework zum parallelen Computing großer Datensätze auf verschiedenen Knoten innerhalb großer Cluster. Da das Prozessing und die Verwaltung von Daten naturgemäß in unmittelbarem Zusammenhang stehen, ist Map-Reduce zusammen mit der Datenbank „HBASE“ auf der Ebene „Distributed data processing“ zu betrachten. Apache HBASE realisert in diesem Zusammenhang Schreib- und Lesezugriff auf das HDFS in Echtzeit und bildet sehr große Tabellen mit Milliarden von Zeilen und Millionen von Spalten in einem Hadoop-Cluster ab.
Zur Hadoop-Famile gehören neben HBASE weitere Tools, die auf dem HDFS- und Map-Reduce-Framework betrieben werden können. Die in Abbildung 1 dargestellten „Top Level abstractions“ zeigen ein beispielhaftes Toolset, um auf den verteilt gespeicherten „Big Data“ Analysen durchführen zu können. Diese Abstraktionsebene bildet die Verknüpfung zwischen den verteilten Systemen in Hadoop und bestehenden Analyseumgebungen in Unternehmen (siehe „Top level interfaces“ in Abbildung 1). So ermöglicht Apache Pig als Plattform für die Implementierung von Datenflüssen in Hadoop eine Integration von ETL-Tools (Extract, Transform, Load). Für den Betrieb von Business Intelligence-Lösungen stellt Apache Hive eine verteilte Data-Warehouse-Infrastruktur zur Verfügung und Apache Sqoop erlaubt den Datentransfer zwischen relationalen Datenbanken (Relational Database Management Systeme) und dem HDFS.
Neben der Verfügbarkeit weiterer Tools, z.B. Ambari, Avro, und Mahout, sowie zusätzlicher Module wie Hadoop YARN, wird im Rahmen des Apache-Projekts die Weiterentwicklung des Hadoop-Frameworks vorangetrieben. Hinsichtlich der Big Data Analysis bietet Hadoop mit HDFS und Map-Reduce also nicht nur eine Antwort auf die heutigen Herausforderungen der Skalierbarkeit, Verfügbarkeit und Performance, sondern auch auf die notwendige Flexibilität bei der Integration von Big Data Analytics in Unternehmen.
Die Implementierung von Big Data-Lösungen in großen Unternehmen ist jedoch angesichts einer Vielzahl von Legacy-Systemen mit Hindernissen konfrontiert. Denn zu den bestehenden Architekturen, Technologien und Applikationen unterschiedlichster Herkunft und Technologiekultur gesellen sich diverse Compliance-Richtlinien sowie Sicherheitspolicies. Daraus ergeben sich für Einführung von Big Data-Technologien notwendige Implikationen für die Organisation:
- Einführung von Prozeduren, Methoden und Skills zur Umsetzung und zum Betrieb der Big Data Analytics
- Entwicklung neuer Policies, um die durch Big Data getriebenen Anforderungen an Datenqualität und Datensicherheit zu adressieren
- Sponsoring des Top-Managements zur Sicherstellung einer ganzheitlichen Big Data-Governance
Diese Thematik, die Big Data-Technologien in ihrer Gesamtheit anbelangt, muss in den entsprechenden Kalkülen zur Erschließung von Big Data-Technologien berücksichtigt werden. In den Unternehmen ist das Bewusstsein zu schärfen, welche Herausforderungen durch eine moderne Daten-Plattform überhaupt addressiert werden können und in welchem Rahmen die Organisation selbst die Verantwortung über das Datenmanagement übernehmen muss.
Meet our authors
Artur Burgardt

Artur Burgardt ist Managing Partner bei CORE und spezialisiert auf das Management agiler Umsetzungsprojekte in komplexen Kontexten. Als ausgebildeter theoretischer Physiker sammelte er erste Berufs...
Mehr lesenArtur Burgardt ist Managing Partner bei CORE und spezialisiert auf das Management agiler Umsetzungsprojekte in komplexen Kontexten. Als ausgebildeter theoretischer Physiker sammelte er erste Berufserfahrung als Business Analyst bei großen Finanzdienstleistern und erwarb grundlegende Kenntnisse in der Entwicklung von Kernbankensystemen. Dieser Karriereschritt führte ihn zu CORE. Mit seinem umfangreichen Wissen verantwortet Artur neben den Projekten bei Klient:innen das Knowledge Management bei CORE.
Weniger lesen

