Artificial intelligence in banking: Deep learning vs. gradient boosting
KEY FACTS
- Data analysis and artificial intelligence of increasing social and economic relevance
- Deep learning as a high performance model of artificial intelligence often at the centre of discussion
- Gradient boosting based on decision trees as a performant (function) and interpretable (transparency) model as an alternative in the financial industry
REPORT
"Artificial intelligence" is one of the most discussed topics in public today. Events such as the evaluation of voter data by Cambridge Analytica for the US presidential election in 2016 or the generation of a conversation with the new generation of Google Assistants, which many participants regard as humane, do fuel fears and enthusiasm for the new technology; However, it is only by distinguishing individual methods of artificial intelligence that meaningful application cases and benefit aspects can be critically discussed, i.e. their performance and limitations can be assessed in an economic dimension and assessed against the background of social and legal contexts.
Use of Artificial Intelligence in the Economy
The business models of the technology giants Google, Apple, Facebook and Amazon (GAFAs) as well as those of Baidu, Alibaba and Tencent (BATs) are only made possible by artificial intelligence. The analysis of customer-side data, e.g. master data, usage data or transaction data, allows the appropriate interactions, recommendations or search results to be determined on a customer-specific basis. With their Personal Assistance products (Siri, Alexa and Google Home), they bring artificial intelligence into the everyday lives of customers and support them in their daily problems. Huawei and Baidu on the Chinese market announce competition products for 2018. The result is a constantly growing database of these companies, which in turn enables them to continuously refine statements about future customer behavior.
Data analysis is also becoming increasingly important in the financial sector and is seen as a differentiating competitive factor in the future. For example, JPMorgan Chase recently introduced the "Contract Intelligence" application. This makes it possible to analyze 12,000 commercial credit agreements in a matter of seconds to extract important data points and clauses. The manual contract review would take about 360,000 hours. Companies such as Scalable Capital use algorithms to automate the trading of ETF portfolios and minimize manual processes. In addition, Scalable Capital benefits from the algorithms' ability to systematically abstract large amounts of information in a fraction of a second. This enables fast response times to complex information bases and thus increases returns.
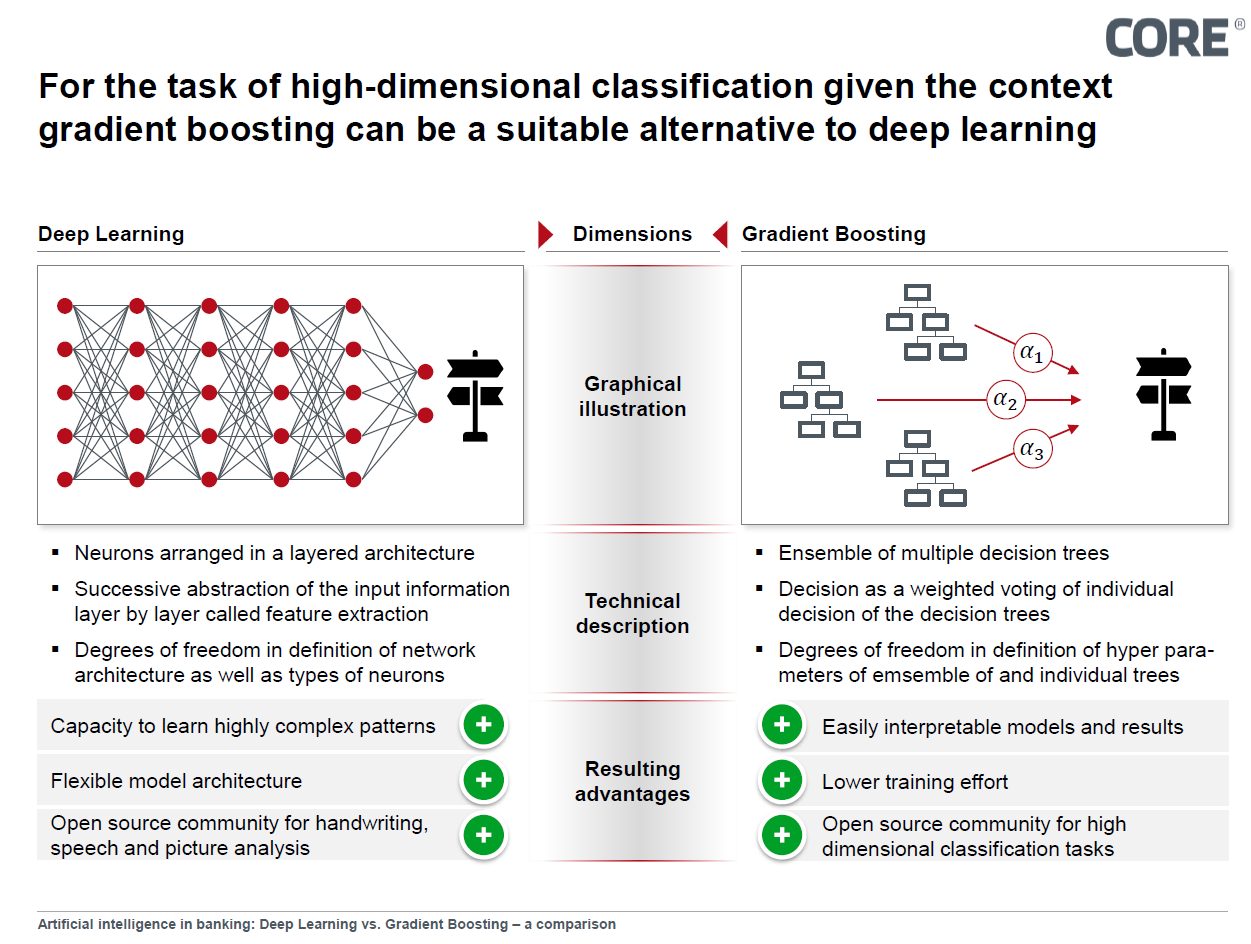
Deep Learning- vs. Gradient Boosting Model
The technology that is most in focus in this discussion is deep learning, an artificial neural network in which functional elements - also known as neurons - are used in a layered network structure to successively process information. Since 2006, these models have been indispensable in the field of high-dimensional classification - the assignment of data points to a limited number of classes in a problem that encompasses many variables. Especially in the field of image, speech and handwriting recognition, there are currently hardly any alternatives to deep learning. These models derive their strength in solving problems from their layered structure. Here, the complex information is abstracted layer by layer until a decision regarding a previously defined problem is finally made in the last layer.
But why is this technology not implemented in every artificial intelligence? The complex structure of a deep learning network also has disadvantages. In order to train the layer-based structure, a comparatively large amount of data and a high level of computing power is required, depending on the depth of the model, i.e. the number of layers implemented. Depending on the application, it may also be necessary to understand the reasons for a decision made by the network. Especially in more strongly regulated contexts, such as banks or insurance companies, traceability can be a mandatory prerequisite. Here it is true that the BaFin has made it unmistakably clear in its current publication from the series BaFin Perspectives 1/2018 that the supervisory authority does not accept an argument according to which the functionality of an algorithm is no longer comprehensible due to its complexity and can therefore no longer be checked by the supervisory authority.
Deep learning nets, with their high number of neurons and links, offer a high learning capacity. However, it is precisely this advantage that prevents a network's decision from being easily or even comprehensible.
A promising alternative to the deep learning approach is ensemble learning, in which various methods and algorithms are combined and which is used particularly in the context of decision trees. In recent years, gradient boosting has been able to assert itself as a subspecies in various public tenders. Instead of making the decision along a single, large decision tree, gradient boosting unites a number of smaller decision trees, each of which is trained to mitigate the weaknesses of other trees. The results of the respective tree are weighted and combined with the results of the other trees to form a joint decision.
Metaphorically speaking, this method represents a group decision by experts, whereby each sub-expert decides optimally for a certain area of the solution space and his decision is weighted in the overall decision. In contrast to deep learning models, this means that a decision of the model can be traced by identifying the trees with the highest contribution to the decision, whereby the decisions of the subtrees are easy to understand. In addition, the complexity of the individual trees in training is often limited, further improving traceability. This limited complexity is a further advantage over the deep learning approach because less data is required for training. In addition, gradient boosting requires relatively little training compared to other high-dimensional classifiers. As a result, gradient boosting promises to lead to a converged training result with a small data set.
RESUME
A statement about the dominance of one of the two models in a particular area is not possible. Both models provide good results in the classification of high-dimensional data, where the performance depends on the underlying data and the patterns it contains. A special case is the task of speech, image and handwriting recognition, in which deep nets are implemented in almost all systems today.
A further decision dimension to be considered - especially in the financial world - are the constraints of the use case in the form of traceability of the model decision or convergence speed (amount of data required up to the trained model), which can lead to a differentiation of the models in addition to the prediction quality. Here, BaFin may already have forced a market prediction.
Depending on the use case and available data, gradient boosting may be preferable, as it leads to better results than deep learning for specific use cases and in terms of transparency. The specific benefits and performance of the gradient boosting model, which is somewhat out of the limelight, will therefore be demonstrated using various use cases and quantified using analyses. The next blog post will deepen the Santander Customer Satisfaction Use Case, a public competition in 2016 to predict customer churn, also known as the Churn Case.
SOURCES
Cambridge Analytica
[German only] “Facebook informiert nach Datenskandal die betroffenen Nutzer”, 10. April 2018:
Engel, C.
“Artificial Intelligence: The Weapon of Choice in Banks’ Fight for Survival”, 07. March 2018:
https://thefinancialbrand.com/71108/artificial-intelligence-banking-machine-learning/
Kaggle: Stantander Customer Satisfaction
“Santander Customer Satisfaction - Which customers are happy customers?”:
https://www.kaggle.com/c/santander-customer-satisfaction
Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin)
“BaFin Perspektiven. Ausgabe 1/2018”:


