From theory to practice. Current artificial intelligence models in the finance industry
KEY FACTS
-
The EBA is finalizing Regulatory Technical Standards (RTS) on strong customer authentication and more secure communication for cash-free transactions
-
Final confirmation of the compulsory provision of the PSD II interface for third-party payment service providers (TPPs) – meaning screen scraping is no longer necessary and will be prohibited
-
Regulation on mandatory strong customer authentication (SCA) has been adjusted in response to feedback from the market. The limit applicable to exempting remote payments has been raised from €10 to €30. SCA will now only need to be repeated for account information services every 90 days instead of the original 30, and biometric methods can be used for SCA without restriction.
-
Two new exemptions to be made for SCA, namely transaction risk analysis (TRA) and non-manned terminals
-
Overall, the EBA is creating a balanced, market-oriented regulation. Banks are summoned once again to compete technologically following the introduction of the exemption-based TRA.
REPORT
Artificial intelligence is undoubtedly one of the most highly discussed technology topics at present. You will struggle to find any mass media source which does not contain any reference to machine learning, deep learning or artificial intelligence. There is a great discrepancy, however, between the public-social discourse on the one hand, with its concerns on the impact on the working world, safety issues (e.g. autonomous driving) and the effects of third-party automated decisions and the debates held among experts concerning methods, technical issues and possible applications involving this new technology on the other.
The Finance Summit took place in London from March 15th-16th, with this year’s topics devoted solely to deep learning. Participants from various sectors of the finance industry were able to exchange their experiences and discuss the challenges posed by applications, particularly with regards to asset management and the insurance sector. We observed a shift in the focus of discussion surrounding deep learning. Whereas last year’s topics primarily focused on more efficient analysis models and promising new applications for text, voice, audio or image recognition, this year the spotlight was on more concrete and detailed case studies of application, whose underlying models were already widely known. Relevant topics this year included
-
the interpretability of models
-
the integration of various data sources as well as
-
correctly evaluating model performance
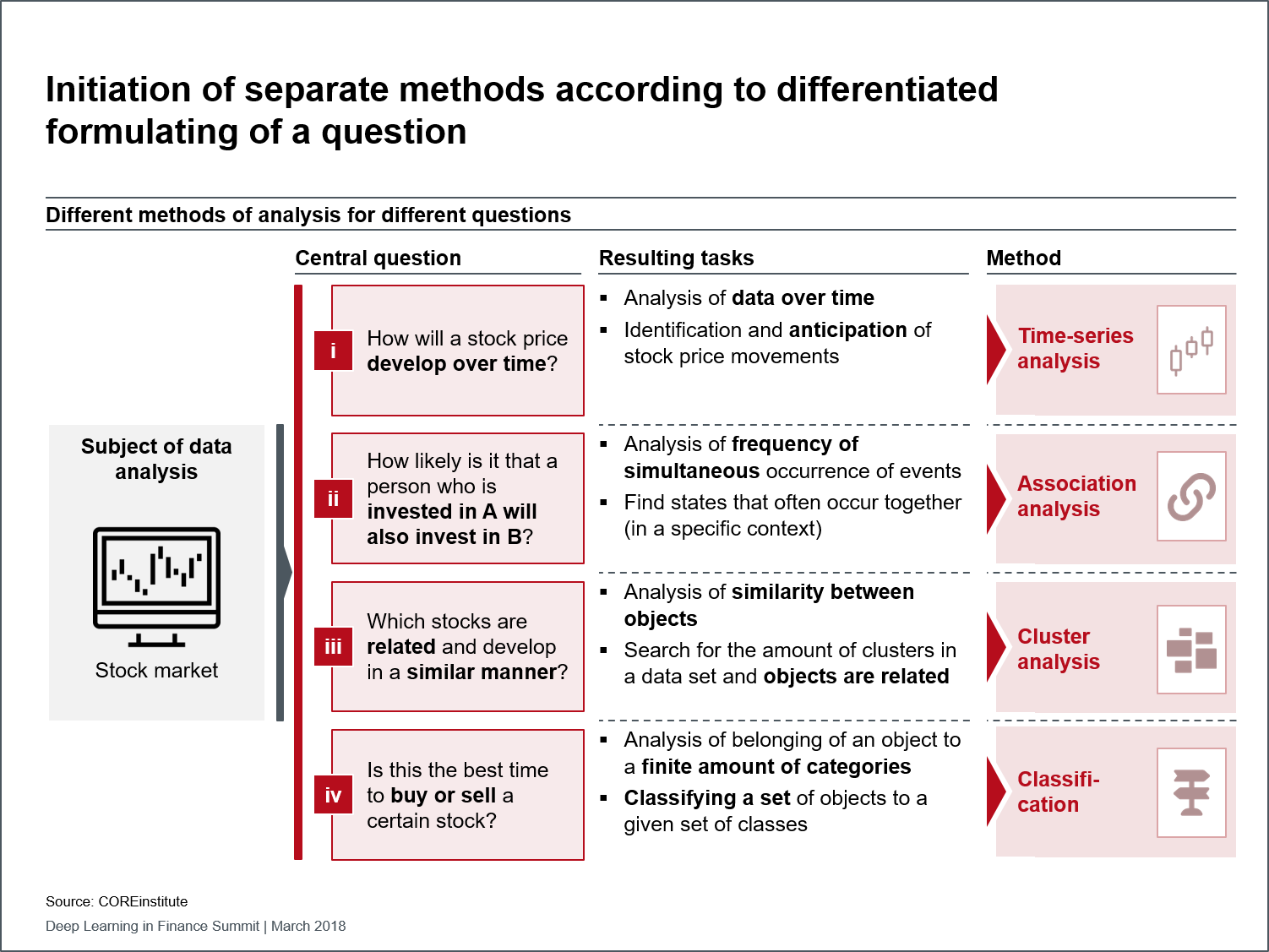
Figure 1: Initiation of separate methods according to differentiated formulating of a question
In contrast to decision trees or graphic probability approaches, for instance, deep learning models are usually unable to identify why a particular decision was reached because of the large amount of parameters involved and random initialization. Regulatory requirements, as well as the credibility of a model, therefore increasingly rely on the interpretability of these models. One approach is to roughly track which elements of the input data have influenced the decision by observing partial results or tracing the gradient in the network. In asset management, for example, this can be used to identify key data sources for courses. It is also crucial to demonstrate the solutions for this problem, as this is necessary in order to enable targeted optimization.
In order to create a reliable decision support system, it is increasingly necessary to include data from multiple sources in the respective model. This is why imagery, linguistic and text information sources ought to be used alongside the low-dimensional sources already in use – for which deep learning is particularly suitable. Best practices reveal how data sources, for example, can be preprocessed using autoencoders, in order to ultimately process them in a common model. Insurers, for example, can use autoencoders to reduce the number of forms required to the key points, which can then be processed automatically.
Today, the performance of a model is either determined by the AUC (area under curve) i.e. the area under the ROC curve (receiver operating characteristic curve used to evaluate the classifier performance) or the misclassification rate (percentage of data points that the model assesses incorrectly). Although these assessments are easy to communicate as they provide an intuitive visual reference to the model’s performance, they can also be counterproductive for various issues. More specific methods which have to be determined according to the problem, allow for a more targeted assessment of deep learning models. This, in turn, makes it possible to find suitable solutions for the respective problem. When applied to a hospital, for example, where 2% of patients are suffering from an identifiable disease, a classifier which would assume that all patients are healthy, would only produce a misclassification percentage of 2%, which, in theory, represents quite a good degree of accuracy. In practice, however, it would actually be more beneficial to have a classifier with a misclassification percentage of even 10% if it were to classify all sick people correctly. In this case it would be better to have a weighted miscalculation rate.
The use of deep learning in asset management was presented with a pragmatic approach at the conference using a variety of examples. Deep learning models, for example, are used to predict price or volatility changes in the market.
They are also used in the insurance sector in order to assess how losses are handled with data from both structured and unstructured sources combined to decide whether to reject or accept the case.
It should, nevertheless, be noted that deep learning cannot address all of the tasks in the financial world. The appropriate use of the model depends primarily on the questions posed on the business side of things. Specific analysis methods are selected depending on how these questions and their related insights are respectively posed and formulated, as exemplified with a question concerning the development of a share price (see figure). Deep learning models are typically classified with time series and classification models (numbers 1 and 3 shown in figure).
Conclusion
The theoretical models discussed at the conferences in previous years have gradually been enhanced using case studies of application. Although it was apparently only detailed application issues that were discussed at this year’s Finance Summit in London, there are indeed direct correlations to the social discourse:
-
Possible solutions to ensure transparency of automated decision-making processes, in order to be able to account for them in an understandable and traceable manner
-
The use of deep learning with regards to higher-dimensional data and combining these, in order to satisfy the complex requirements of the real world
-
The ability to select appropriate deep learning models in light of specific analytical needs in order to use artificial intelligence in a targeted manner
Advancements in the practical applications of artificial intelligence show that it can be effectively put into practice, especially in the further automation of processes and in order to gain new insights from data analysis. In turn, the critical reflection of its own boundaries reveal that even professionals are anything but naive when it comes to working with this technology and its practical applications.
SOURCES
Internet:
Deep Learning in Finance Summit
https://www.re-work.co/events/deep-learning-in-finance-summit-london-2018


