Von der Theorie zur Praxis. Aktuelle Modelle der Künstlichen Intelligenz in der Finanzindustrie
KEY FACTS
- Finance Summit in London am 15./16. März thematisiert konkretere Anwendungsbereiche und Fachprobleme des Deep Learnings in der Finanzindustrie
-
Generell fortgeschrittene Anwendungsreife von Deep Learning-Methoden mit vielfältigen Anwendungsansätzen in Kundeninteraktion, Risikomanagement und Portfoliotheorie
-
Schwerpunkte der Fachdiskussionen auf Interpretierbarkeit von Modellen, Integration verschiedener Datenquellen sowie Bewertung der Modellperformance
-
Weiterhin große Auswirkungen des Deep Learnings auf Methoden und Prozesse in der Finanzindustrie zu erwarten – offene Diskussion der Grenzen dieser Technologie indiziert höheren Reifegrad nach dem Hype der vergangenen Zeit
REPORT
Eines der aktuell meistdiskutierten Technologiethemen ist zweifelsohne das der Künstlichen Intelligenz. Kaum ein Massenmedium erscheint heute ohne Beiträge zu Machine Learning, Deep Learning oder Artificial Intelligence. Dabei ist ein großes Missverhältnis festzustellen zwischen erstens dem öffentlich-gesellschaftlichen Diskurs mit seinen Fragen nach den Auswirkungen auf die Arbeitswelt, auf Sicherheit (z.B. autonomes Fahren) und die Einwirkung aus fremder, maschineller Entscheidung einerseits und andererseits den Diskussionen unter Fachleuten zu den Methoden, fachlichen Problemstellungen und Einsatzmöglichkeiten dieser noch jungen Technologie.
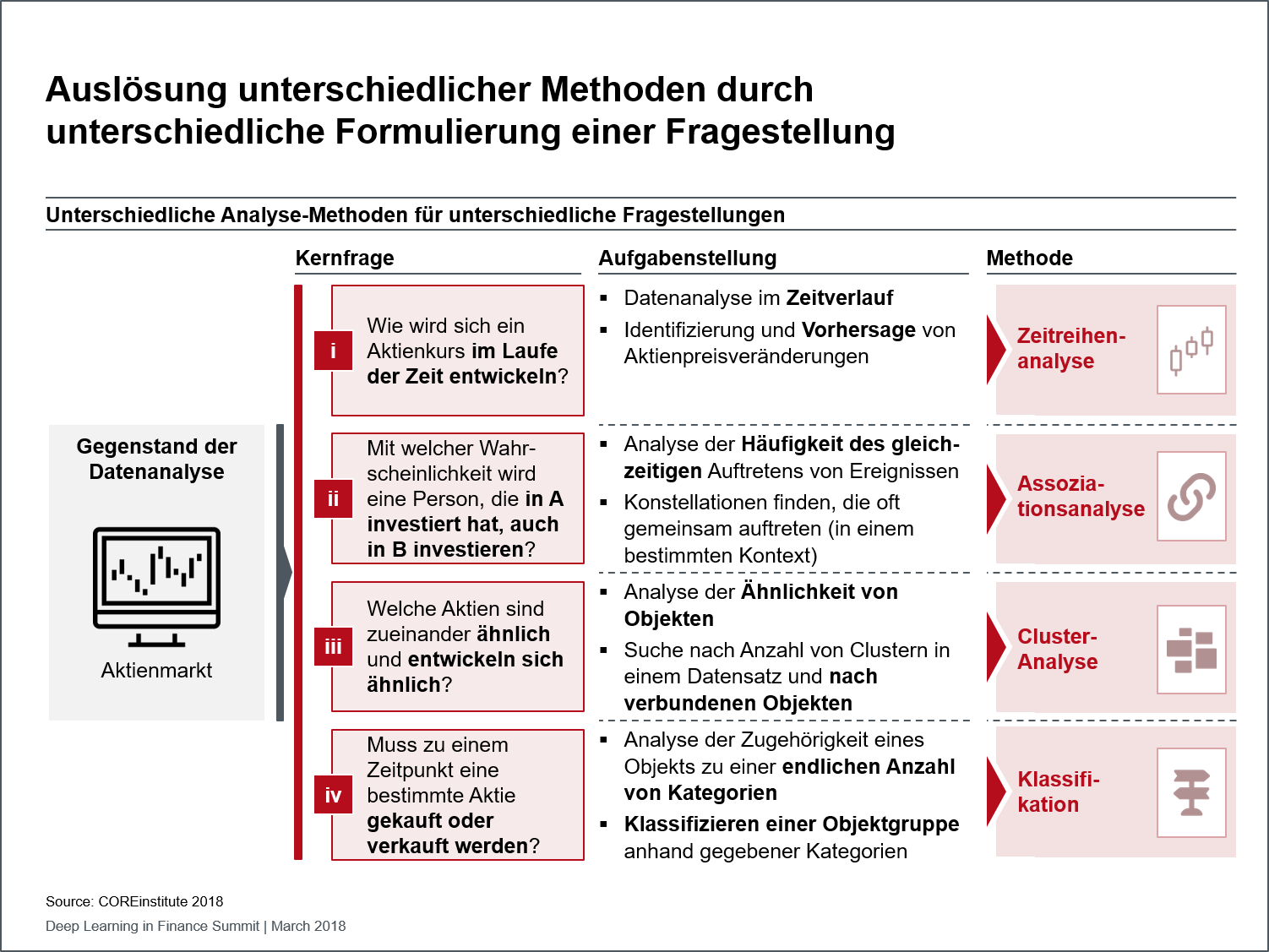
Abbildung 1: Unterschiedliche Analyse-Methoden für unterschiedliche Fragestellungen
Vom 15. bis 16. März fand in London der Finance Summit statt, der sich in diesem Jahr ganz dem Deep Learning widmete. Teilnehmer aus verschiedenen Bereichen der Finanzindustrie konnten Erfahrungen austauschen und die Herausforderungen rund um Anwendungen insbesondere im Asset Management und im Kontext von Versicherungen diskutieren. Dabei zeigte sich eine Verlagerung in der Art und Weise, wie über Deep Learning diskutiert wird. Ging es im Vorjahr vornehmlich um neue, leistungsstärkere Analysemodelle und vielversprechende neuartige Anwendungsfälle zur Text-, Sprach-, Audio- oder Bilderkennung, rückten in diesem Jahr konkretere und detailliertere Use Cases in den Vordergrund, deren zugrundeliegende Modelle im Allgemeinen bekannt sind. Relevante Themengebiete dieses Jahres waren
- die Interpretierbarkeit von Modellen,
- die Integration unterschiedlicher Datenquellen sowie
- die passende Bewertung der Modellperformance
Im Gegensatz etwa zu Entscheidungsbäumen oder graphischen probabilistischen Ansätzen ist bei Deep Learning-Modellen aufgrund der großen Menge an enthaltenen Parametern und zufälliger Initialisierung im Regelfall nicht zu identifizieren, weshalb eine bestimmte Entscheidung getroffen wurde. Regulatorische Anforderungen – und auch die Glaubwürdigkeit eines Modells – setzen daher zunehmend auf die Interpretierbarkeit dieser Modelle. Ein Lösungsansatz besteht darin, durch Beobachtung von Teilergebnissen oder durch Rückverfolgung des Gradienten durch das Netz grob nachzuverfolgen, welche Elemente der Input-Daten die Entscheidung maßgeblich beeinflusst haben. Im Asset Management beispielsweise kann dies dazu genutzt werden, ausschlaggebende Datenquellen für Kurse zu identifizieren. Für diese Problemstellung Lösungen aufzuzeigen ist auch deshalb notwendig, weil die Möglichkeit gezielter Optimierung davon abhängt.
Für eine belastbare Entscheidungsunterstützung ist es zunehmend notwendig, Daten aus vielfältigen Quellen in ein Modell einzubeziehen. Neben den bereits verwendeten niederdimensionalen Quellen sollen daher Bild-, Sprach- und Textinformationen – wofür sich Deep Learning als Methode grundsätzlich besonders gut eignet – genutzt werden. Best Practices zeigen auf, wie Datenquellen z.B. mithilfe von Autoencodern vorverarbeitet werden können, um sie schließlich in einem gemeinsamen Modell zu prozessieren. Versicherer können beispielsweise Autoencoder nutzen, um Formblätter auf wichtige Informationen zu reduzieren, die dann automatisch weiterverarbeitet werden können.
Die Performance eines Modells wird heutzutage entweder anhand der AUC (Area Under Curve und damit Fläche unter der ROC-Kurve – Receiver Operating Characteristic- oder Grenzwertoptimierungskurve, die zur Evaluation der Klassifikatorperformance genutzt wird) oder der Missklassifikationsrate (Anteil der Datenpunkte, die das Modell falsch bewertet) beurteilt. Diese Bewertungen sind zwar leicht zu kommunizieren, da sie einen intuitiv-visuellen Bezug zur Leistung des Modells vorweisen, doch können sie in verschiedenen Problemstellungen kontraproduktiv wirken. Genauere Methoden, die problemabhängig bestimmt werden müssen, erlauben eine gezieltere Beurteilung von Deep Learning-Modellen. Das wiederum ermöglicht, die für das jeweilige Problem passendsten Lösungen zu finden. Für ein Krankenhaus beispielsweise, in dem 2% der Patienten an einer zu erkennenden Krankheit leiden, würde ein Klassifikator, der alle Patienten gesund schätzen würde, nur eine Missklassifikation von 2% vorweisen, was theoretisch ein gutes Ergebnis darstellen würde. In der Realität wäre allerdings ein Klassifikator sinnvoller, der zwar 10% falsch, im Gegenzug aber alle Kranken korrekt klassifizieren würde. In diesem Fall wäre eine möglicherweise gewichtete Missklassifikationsrate vorzuziehen.
Der Einsatz von Deep Learning im Asset Management wurde auf der Konferenz realitätsnah anhand verschiedener Beispiele dargestellt. So werden Deep Learning-Modelle beispielsweise dazu verwendet, Kurs- oder Volatilitätsveränderungen des Marktes zu prognostizieren. Daneben kommen Deep Learning-Modelle im Versicherungsbereich zum Einsatz, um Schadensfälle hinsichtlich ihrer Abwicklung zu bewerten. Dabei werden Daten aus strukturierten Quellen mit unstrukturierten Textquellen kombiniert, um über Ablehnung oder Annahme des Falls zu entscheiden.
Es bleibt allerdings festzuhalten, dass Deep Learning nicht alle Aufgabenstellungen in der Finanzwelt wird adressieren können. Der passende Einsatz des Modells ist in erster Linie von der zu beantwortenden Fragestellung der Business-Seite abhängig. Je nachdem, wie diese Frage und das zugehörige Erkenntnisinteresse gestellt und konkret formuliert werden, sind jeweils spezifische Analyse-Methoden zu wählen, wie am Beispiel einer Fragestellung zur Entwicklung eines Aktienkurses exemplifiziert werden kann (siehe Abbildung). Deep Learning-Modelle sind typischerweise bei den Zeitreihen- und Klassifikationsmodellen anzusiedeln (Nummern 1 und 3 der Abbildung).
Fazit
Die auf den Konferenzen der vergangenen Jahre diskutierten theoretischen Modelle werden sukzessive um Anwendungsbezüge ergänzt. Doch auch wenn es scheinbar nur geringfügige Detail-Anwendungsfragen waren, die auf dem diesjährigen Finance Summit in London diskutiert wurden, so zeigen sich doch direkt die Zusammenhänge zum gesellschaftlichen Diskurs.
- Lösungsansätze zur Sicherstellung der Transparenz maschineller Entscheidungen, um nachvollziehbar und nachverfolgbar Rechenschaft geben zu können
- Nutzung des Deep Learnings auf höherdimensionale Daten und deren Kombination, um der Komplexität der realen Welt zu genügen
- Die Fähigkeit, angesichts spezifischer Analysebedarfe passende Deep Learning-Modelle auszuwählen, um Künstliche Intelligenz differenzierter einzusetzen
Die Fortschritte im Anwendungskontext der Künstlichen Intelligenz zeigen, dass sie insbesondere zur weiteren Automatisierung von Prozessen sowie zur Gewinnung von neuen Erkenntnissen aus der Datenanalyse eingesetzt wird. Die kritische Reflexion ihrer eigenen Grenzen wiederum macht darauf aufmerksam, dass auch die Fachwelt alles andere als naiv mit dieser Technologie und ihren Einsatzmöglichkeiten umgeht.
SOURCES
Internet:
Deep Learning in Finance Summit
https://www.re-work.co/events/deep-learning-in-finance-summit-london-2018


